Search Engine Project
Jerry Zhou, Zhen Tong
Video Link: https://drive.google.com/file/d/13MdECAUIdQNq1wylJjx80B8CngMurkSy/view?usp=sharing
Github link: https://github.com/58191554/Search-Engine-with-GKE-Kafka-and-Dataproc-Hadoop
In this project, we build a search engine system using Kafka and MapReduce. The system is deployed on Google Cloud Platform, using GKE and Google Dataproc. The deployment is done through terraform.
Search Client
Upload File
Using the Google Cloud Storage API, the search client can upload files to the GCP bucket.
Producer
The producer is a python script that uses the Kafka Python client to produce messages to the Kafka topic. The message format is:
key: job_id
value: search_term, n_value
The producer will maintain a table of jobs. When the consumer completes a job, it will send a message to the producer to update the job status.
| job_id | search_term | result |
| 1 | "bridge" | None |
| 2 | "house" | None |
Update Result
The consuer can post the result of Hadoop job to the producer. The producer will update the job result in the table.
Frontend Layout
Users can upload files to the GCP bucket and submit a search job. The producer will produce a message to the Kafka topic. The consumer will consume the message and submit a Hadoop job. When the Hadoop job is completed, the consumer will post the result to the producer. The producer will update the job result in the table.
MapReduce Consumer
Consumer
The consumer is a python script that consumes messages from the Kafka topic. Each message is packed as a json object. The trigger will submit the json object as a Hadoop job. After the job is completed, the consumer will post the result to the producer. After hadoop result is posted, the consumer will continue consuming the next message from the Kafka topic.
MapReduce Job
The MapReduce job use the inverted index algorithm to count the frequency of each word in the file. Given a search term, the mapper will use the "-cmdenv", f"SEARCH_WORD={target_term}" and the compacted .gz file as a input for the Hadoop job. The output of mapper is:
/path/to/Hugo.gz 1
/path/to/Hugo.gz 1
/path/to/Hugo.gz 1
/path/to/Shakespeare.gz 1
/path/to/Tolstoy.gz 1
/path/to/Tolstoy.gz 1
...
The reducer will receive the output of mapper and count the frequency of the search term in the file. The output of reducer is:
/path/to/Hugo.gz 3
/path/to/Shakespeare.gz 1
/path/to/Tolstoy.gz 2
...
Trigger
The trigger will submit the json object as a Hadoop job. It will also get the response Hadoop job id, and iterative consult the Hadoop job status. When the Hadoop job is completed, the trigger download the reducer output from the Google Cloud Storage bucket and post the result to the producer.
Kafka
The terraform code to launch the Kafka cluster is in the terraform-kafka folder. This will automatically launch a Kafka cluster. The advertised listener is dynamically assigned when the kafka broker loadblancer service is created. You can refer to terraform-kafka/kubernetes.tf to see the details.
env {
name = "KAFKA_ADVERTISED_LISTENERS"value = "PLAINTEXT://broker:29092,PLAINTEXT_HOST://${local.kafka_lb_ip}:9092"
}Google Dataproc
The terraform code to launch the Google Dataproc cluster is in the terraform-dataproc folder. This will automatically launch a Google Dataproc cluster, with Hadoop map reduce framework installed. To triger the MapReduce job, You need to make sure mapper.py and reducer.py are in the GCP bucket. And there should be a /Data/ folder in the GCP bucket.
How to run the project
Visite the dockerhub page:
- mapreduce-consumer: https://hub.docker.com/repository/docker/zhentong123/clinfra-mr-consumer/general
The Google Dataproc and GKE is split in two terraform code. You need to deploy both of them.
cd terraform-dataproc
terraform init
terraform apply
cd ../terraform-kafka
terraform init
terraform apply
Output Screenshots
Search Client
Upload file or submit search job:
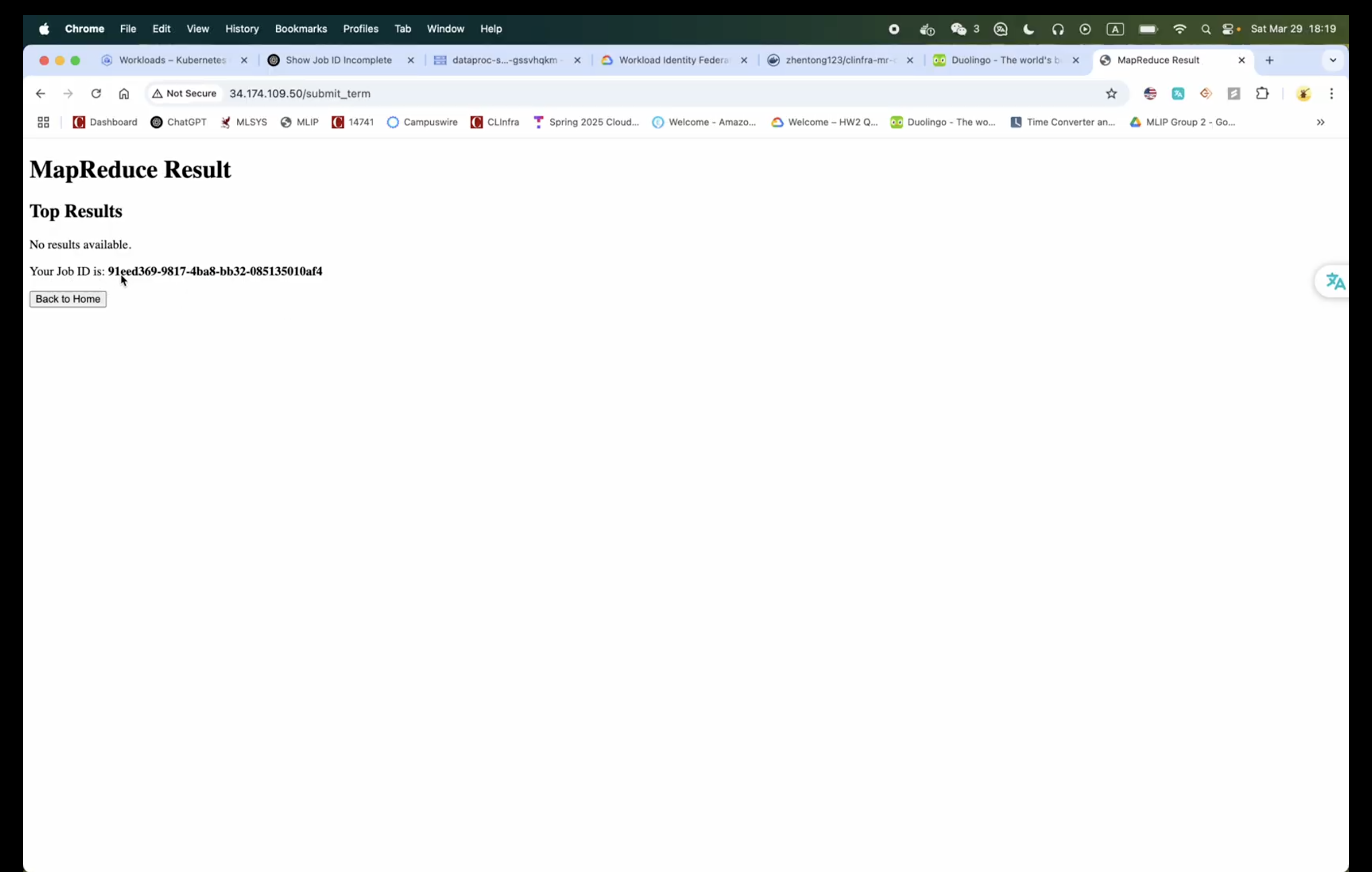
Waiting for search:
MapReduce Consumer
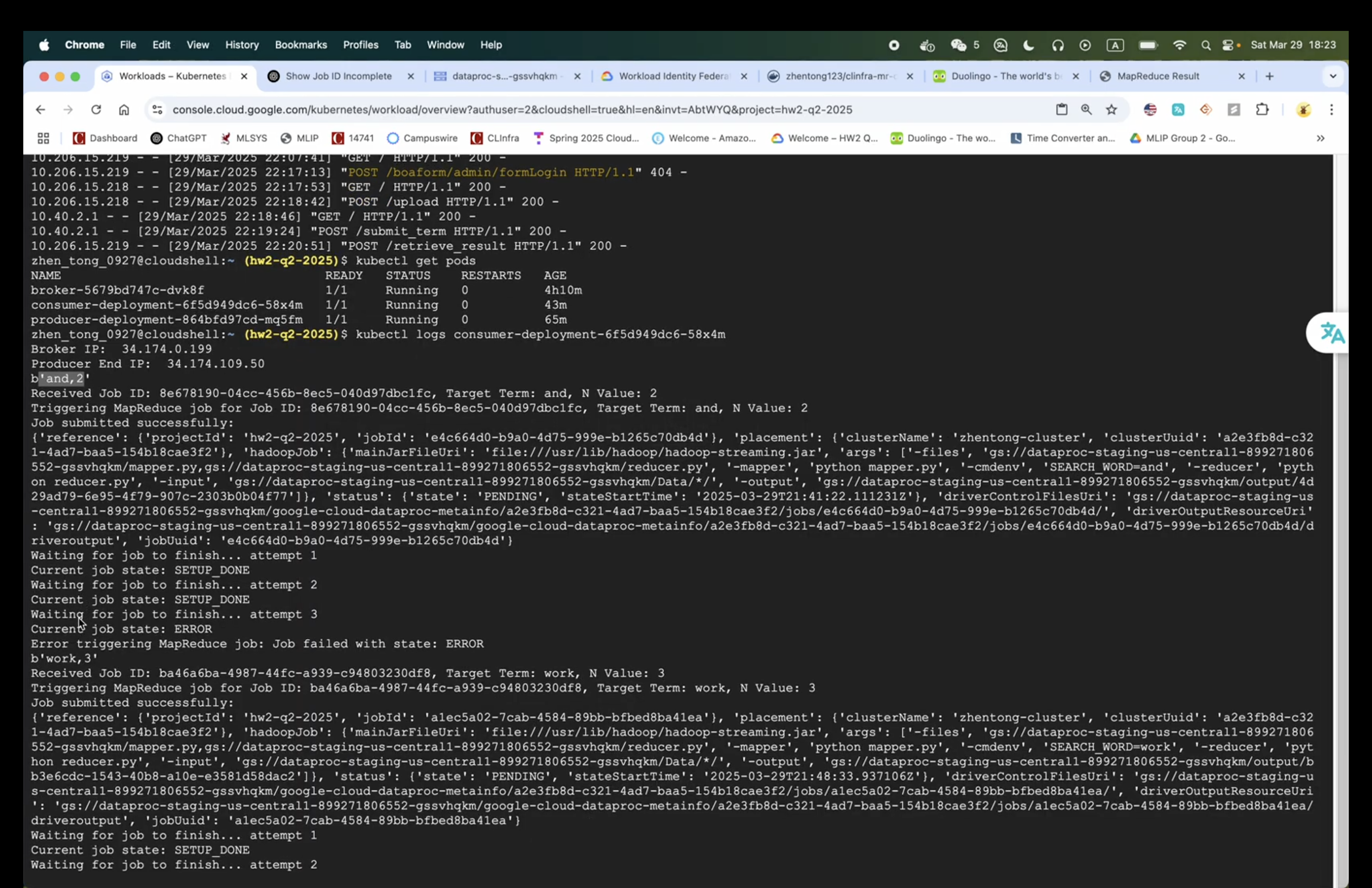
The hadoop job execution:
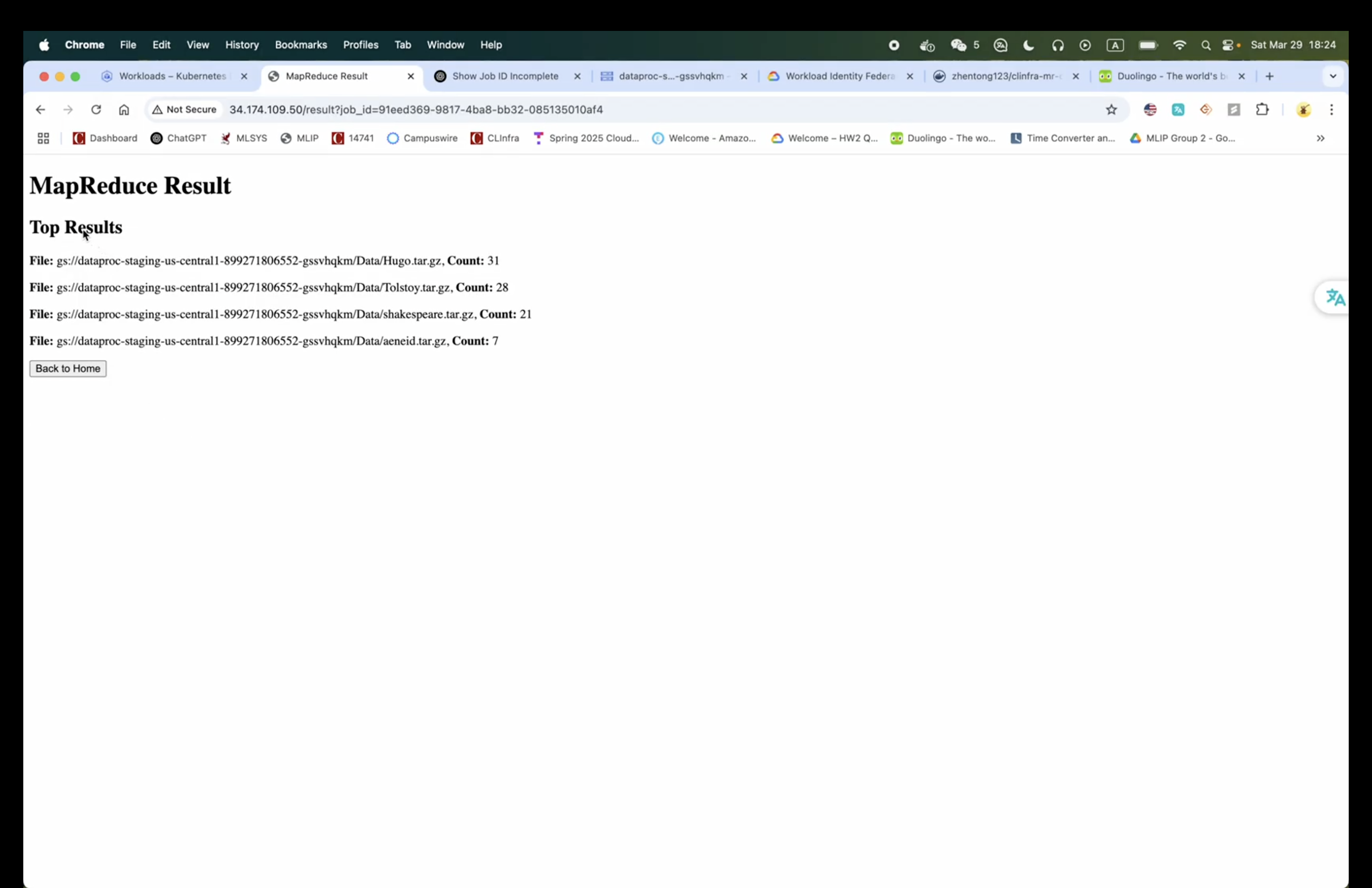
MapReduce Result
Common Issues
Set the kafka broker ip
If you run on a linux machine, and got this:
zhen_tong_0927@cloudshell:~ (hw2-q2-2025)$ docker run --platform linux/amd64 --rm -it --entrypoint /bin/sh zhentong123/clinfra-search-client:1.0.0
Unable to find image 'zhentong123/clinfra-search-client:1.0.0' locally
1.0.0: Pulling from zhentong123/clinfra-search-client
6e909acdb790: Pull complete
cec49b84de9d: Pull complete
da1cbe0d584f: Pull complete
9a95d1744747: Pull complete
e51b7e2231a4: Pull complete
fb4446aa1855: Pull complete
d65f3004c8e2: Pull complete
8a1e1ce4450f: Pull complete
5b532e2af989: Pull complete
Digest: sha256:f91d90ee24dc5dd7654ffd604b0f614c0b21d2d26e8ec6b265d038f1b9e4f34f
Status: Downloaded newer image for zhentong123/clinfra-search-client:1.0.0
# ls -l /app/entrypoint.sh
-rwxr-xr-x 1 root root 276 Mar 29 18:19 /app/entrypoint.sh
# file /app/entrypoint.sh
/bin/sh: 2: file: not found
# sh -x /app/entrypoint.sh
+ [ -z ]
+ echo Error: BROKER environment variable is not set.
Error: BROKER environment variable is not set.
+ exit 1
#
You need to set the BROKER environment variable.
Reference
- How to upload file to GCP bucket from local machine: https://cloud.google.com/storage/docs/uploading-objects